Our four guidebooks (MCP, Agents, DS, and AI Engineering) were only accessible in PDF format so far, which made it difficult for us to update and re-distribute them to you.
To fix this, we have started rolling them out in web versions as well to improve accessibility.
We’ll release the other three Guidebooks as well over the next few days and keep updating them as we release new resources for you in the future.
Reply to this email to let us know if you have any specific requests on what you would like to see next on the website (like roadmaps, features, blueprints, etc.)
Also, in case you missed it…
In just 2 days, the price of lifetime access to DailyDoseofDS will increase by 50%.
It gives you lifetime access to DailyDoseofDS at just 2x the yearly price instead of 3x.
P.S. Our last sale was over 12 months ago. We don’t do Black Friday. We don’t do Cyber Monday. This discount disappears in 2 days, and we have no plans to offer it again.
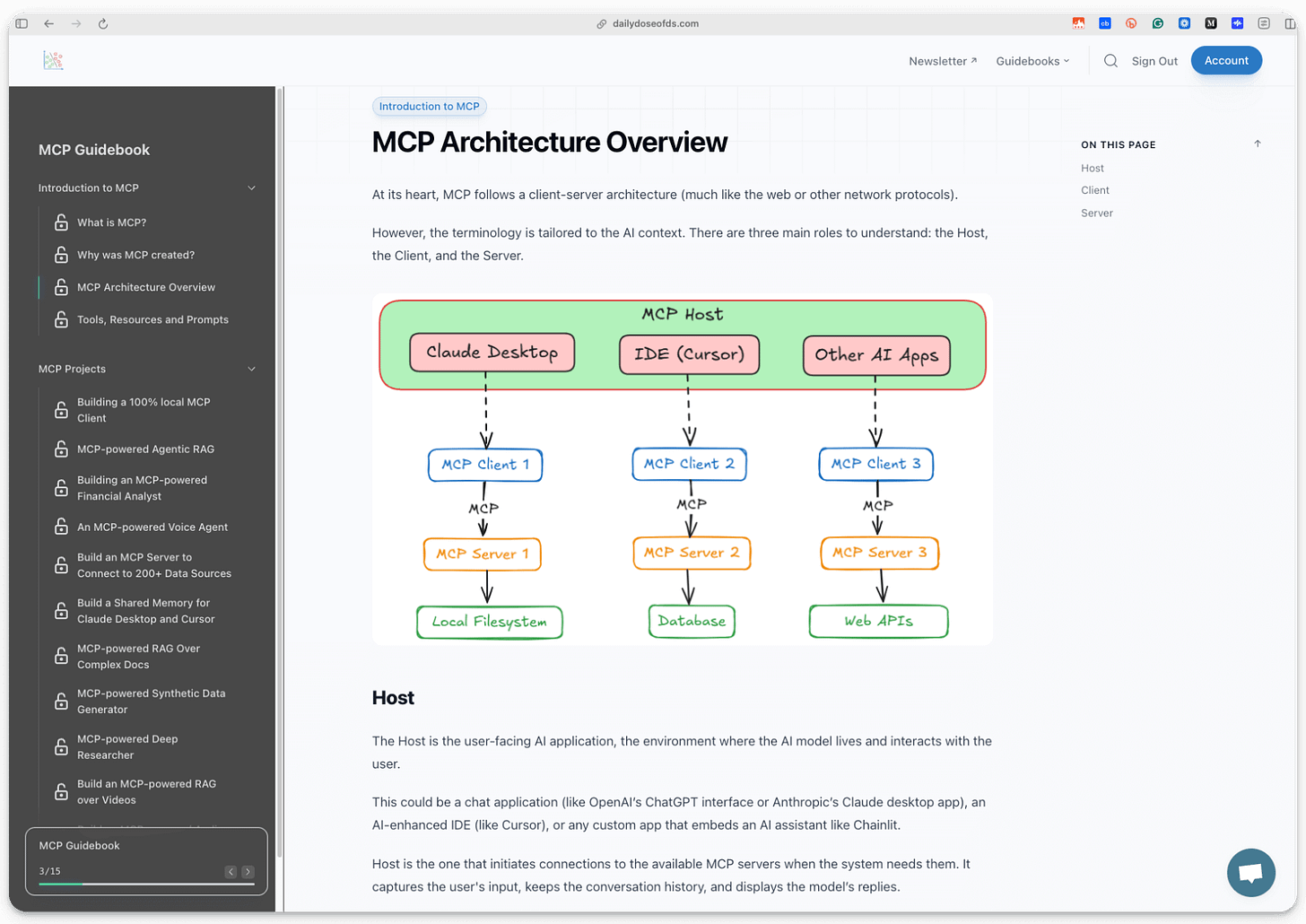
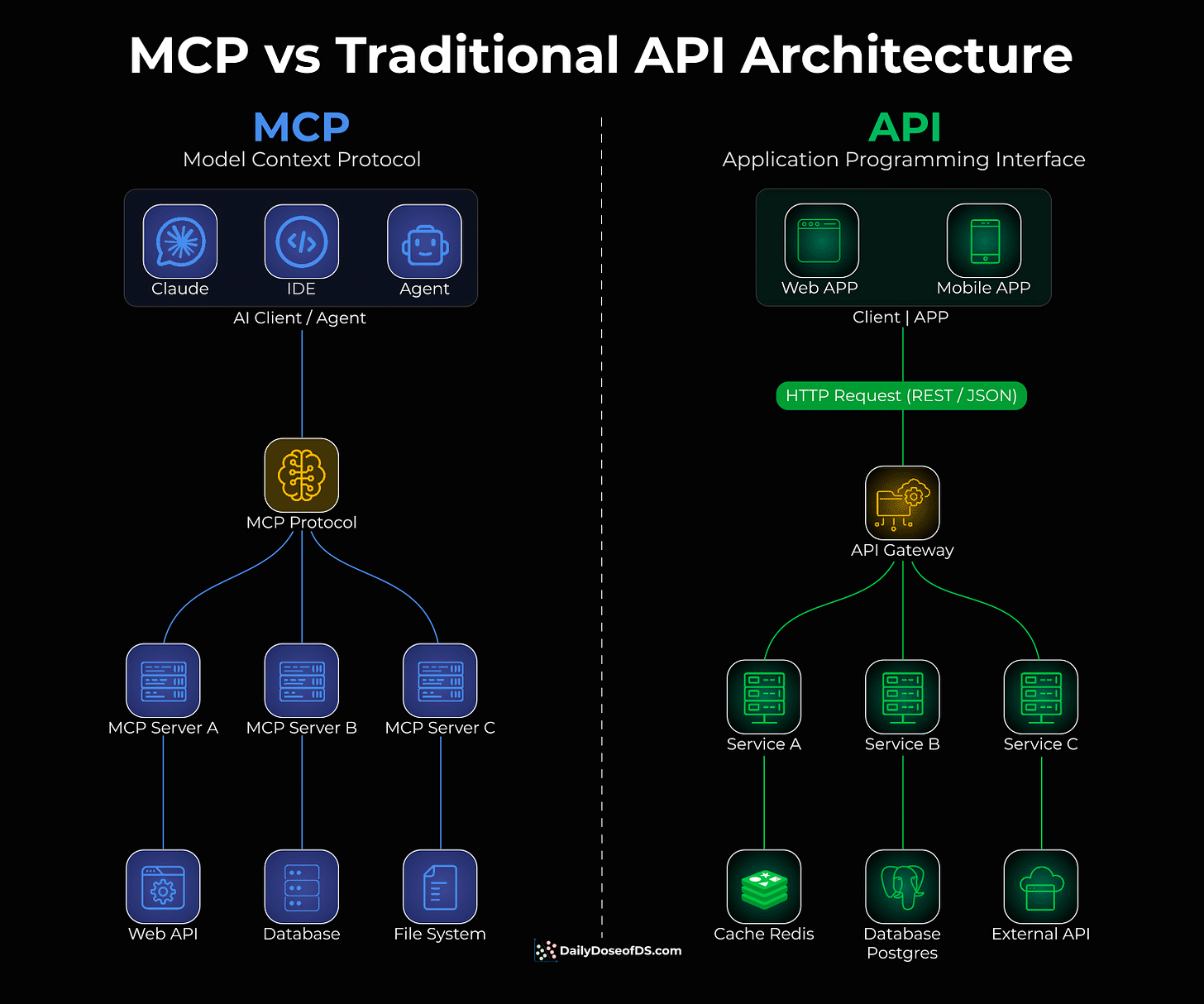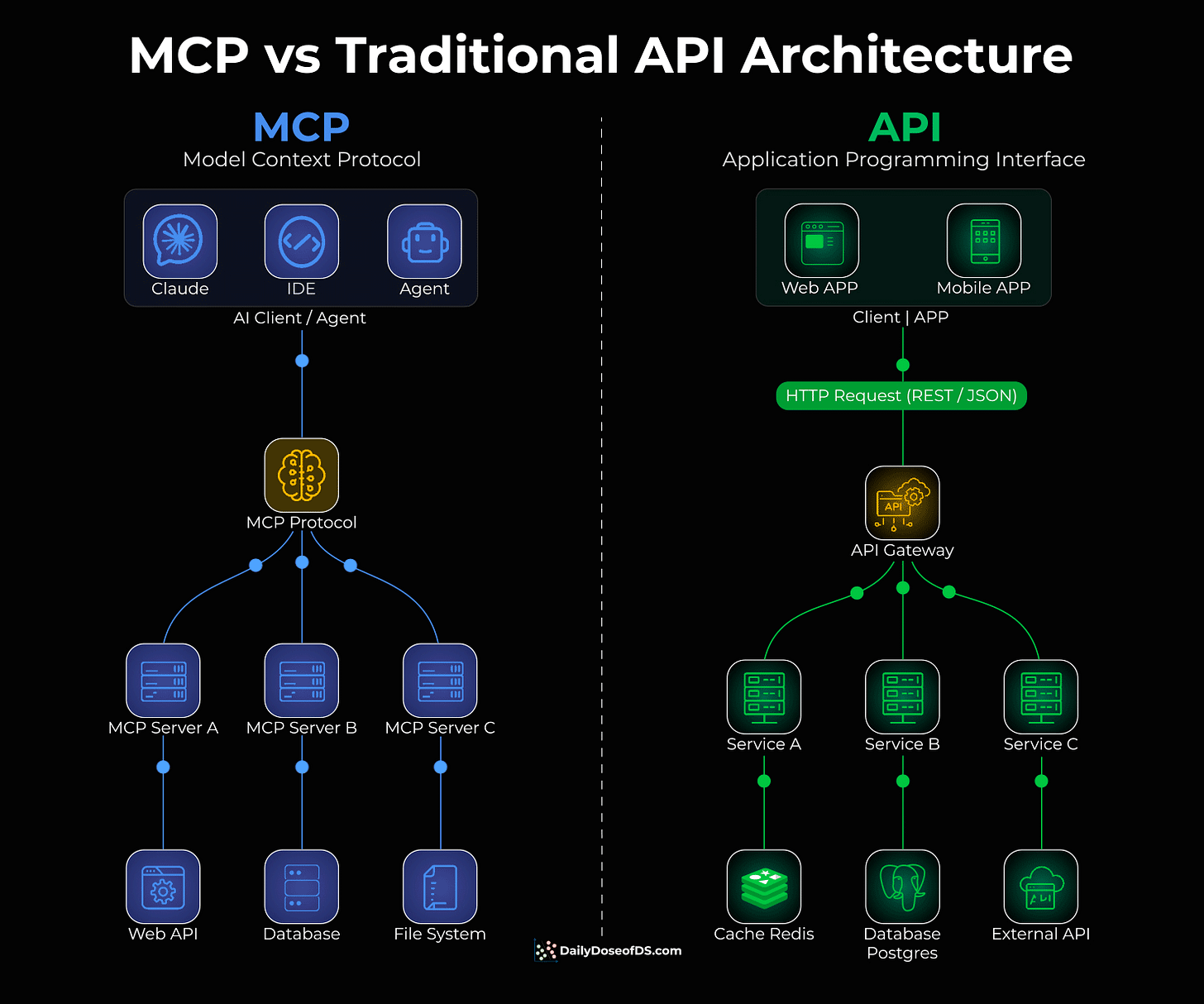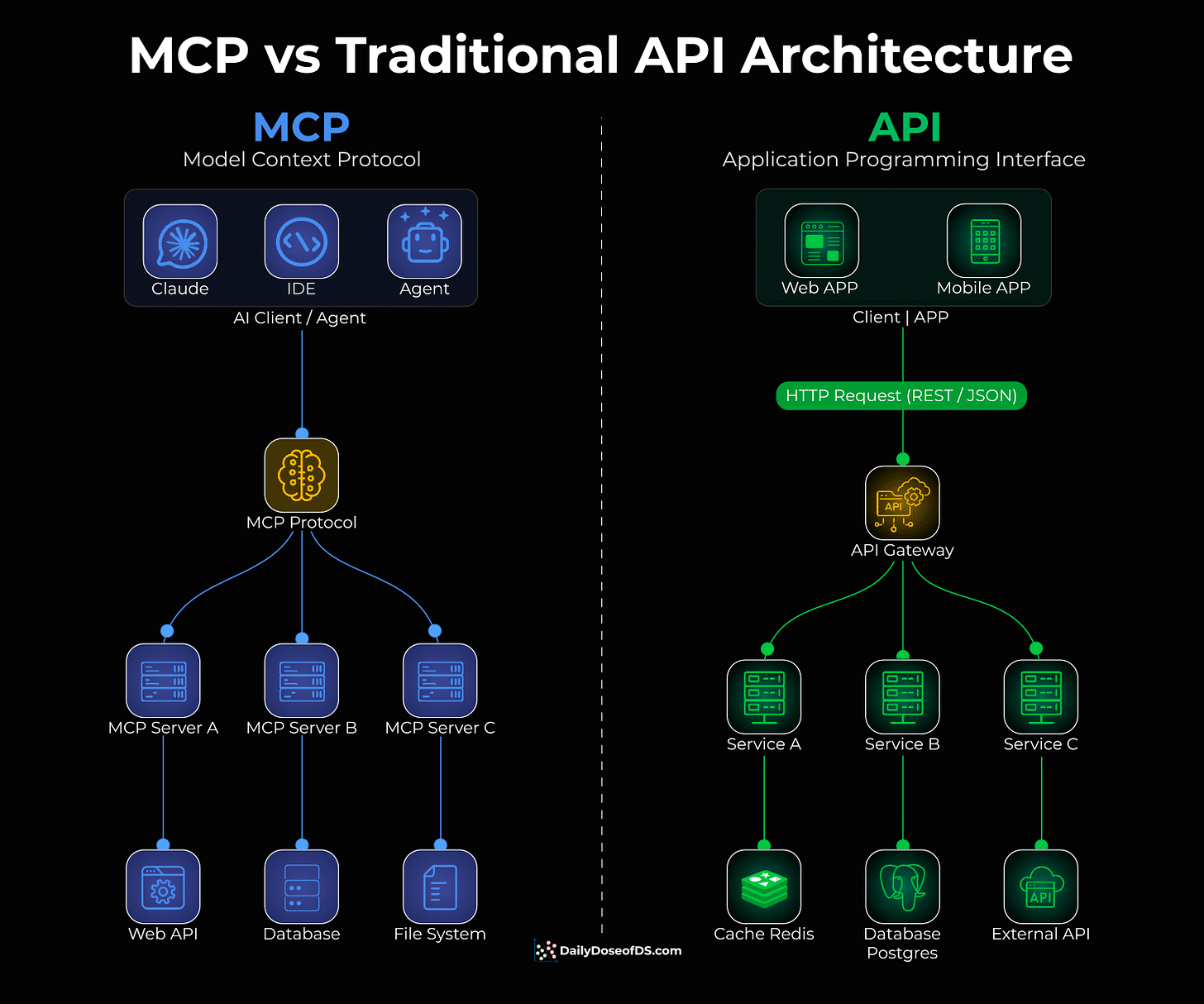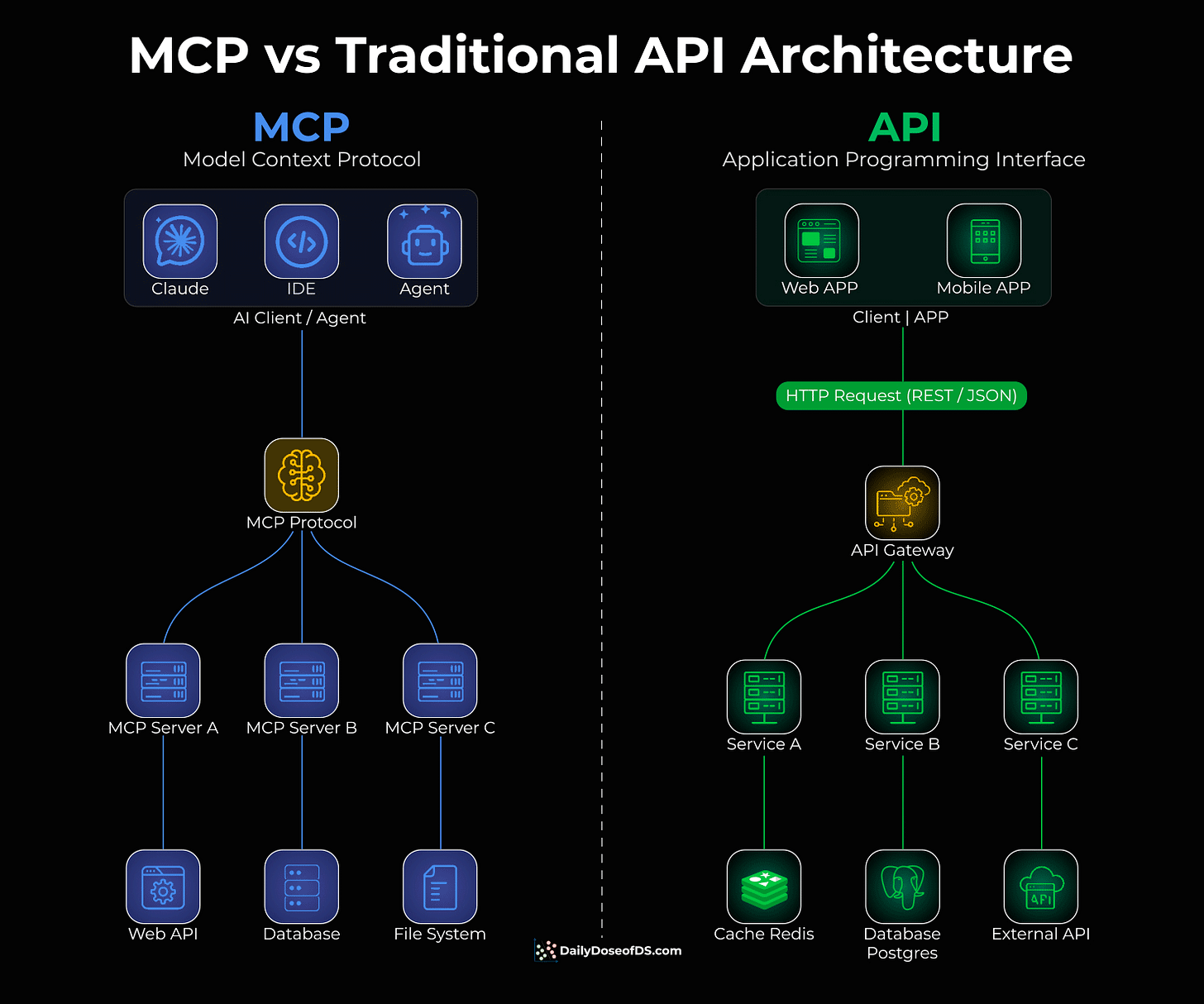
Traditional APIs were built for apps to talk to servers.
You have a client (web or mobile app), which sends HTTP requests through an API gateway, and the gateway routes to different services.
This works great for applications. But AI agents aren’t apps.
Here’s the problem:
When you want an AI agent to use a tool, like querying a database, accessing files, or calling an API, you have to write custom integration code for each one. Every tool is different, and every integration is bespoke.
MCP solves this, and the visual below differentiates the architectural difference.
Instead of building custom integrations, MCP provides a universal protocol that sits between AI clients (Claude, IDEs, agents) and tools/APIs.
One protocol to connect to any tool
The AI doesn’t care what’s behind the server, like a database, file system, web API
Tool providers build one MCP server, and it works with any AI client.
The visual above shows this clearly: instead of an API gateway routing traffic to individual services, MCP creates a universal layer between AI agents and backend resources.
If you don’t know MCPs, read the guidebook shared above.
And if you want to dive into core MCP engineering, we covered all these details (with implementations) in the MCP course:
PyTorch gives so much flexibility and control. But it leads to a ton of boilerplate code.
PyTorch Lightning lets you massively reduce the boilerplate code, and it allows us to use distributed training features like DDP, FSDP, DeepSpeed, mixed precision training, and more, by directly specifying parameters:
But it isn’t as flexible as PyTorch to write manual training loops, etc.
Lately, we have been using Lightning Fabric, which brings together:
The flexibility of PyTorch.
And distributed training features that PyTorch Lightning provides.
You only need to make 4 minor changes to your existing PyTorch code to easily scale it to the largest billion-parameter models/LLMs.
All this is summarized below:
First, create a Fabric object and launch it:
While creating the Fabric object above, you can specify:
the accelerator and the number of devices
the parallelism strategy to use
the floating point precision, etc.
Next, configure the model, the optimizer, and the dataloader:
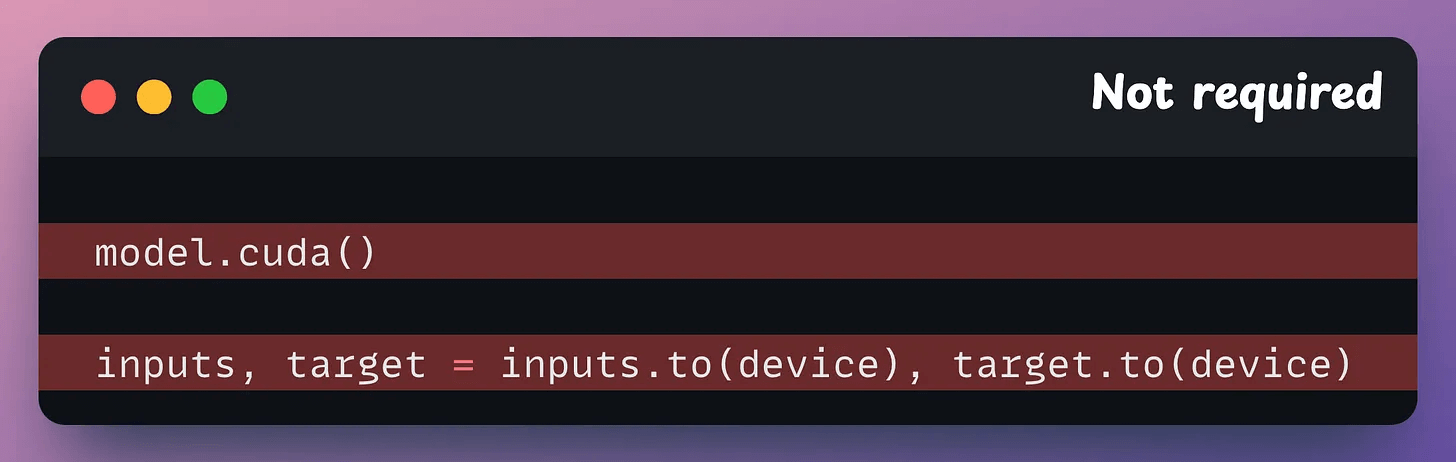
Next, you can remove all .to() and .cuda() calls since Fabric takes care of it automatically:
Finally, replace loss.backward() with fabric.backward(loss):
Done!
Now, you can train the model as you usually would.
These 4 simple steps allow you to:
Easily switch from running on CPU to GPU (Apple Silicon, CUDA, …), TPU, multi-GPU or even multi-node training
Use state-of-the-art distributed training strategies (DDP, FSDP, DeepSpeed) and mixed precision out of the box
Moreover, you can also build your own custom Trainer using Fabric for training checkpointing, logging, and more.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
ADVERTISE TO 900k+ Data Professionals
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., around the world.
Get in touch today by replying to this email.
Today’s email was brought to you by Avi Chawla and Akshay Pachaar.
Master Full-stack AI Engineering In today's newsletter: An Open-Source Autonomous BI Agent. A Memory-efficient technique to train large models. Types of memory in AI Agents. TODAY'S ISSUE Open-source An Open-Source Autonomous BI Agent MindsDB just open-sourced Anton, an autonomous BI agent that turns plain-language questions into full dashboards. You ask something like “Show me NVIDIA’s profit margins,” and Anton handles everything: figuring out the right data source, writing and executing...
Master Full-stack AI Engineering In today's newsletter: Is AI actually saving your engineering team time? Anatomy of the .claude/ folder. TODAY'S ISSUE together with postman Is AI actually saving your engineering team time? Most teams have adopted AI in some form, but the gap between “using AI” and “getting measurable ROI from AI” is larger than people realize. Postman released a cost savings analysis that looks at six common API development workflows and benchmarks the actual time and cost...
Master full-stack AI Engineering In today's newsletter: DailyDoseofDS is now on Instagram! MCP & Skills for AI agents. [Hands-on] Building an open NotebookLM clone! TODAY'S ISSUE AI engineering DailyDoseofDS is now on Instagram! This newsletter regularly breaks down RAG architectures, AI agents, LLM internals, and everything in between. Now we’re bringing all of that to Instagram too, in a format that’s quick to consume and hard to ignore. We’re already 240 posts deep with content on RAG vs...